
蜘蛛池程序:防止爬虫IP被禁

在使用爬虫技术时,需要考虑怎么对付反爬虫技术。
以用户的角度来看,他只想获取网站的数据,对其他的内容完全不感兴趣。以网站方的角度来看,他只想为正常上网用户提供服务。为网络机器人(Python爬虫)提供数据并不能获取有效流量(利益),那么网站以技术(反爬虫技术)拒绝网络爬虫,也就是理所当然应该考虑的了。
双方都有充足的理由,使用起“武器”来自然也是毫不手软。爬虫与反爬虫的斗争一直都在进行着,可能永远都不会停止,到底是矛更加尖锐还是盾更加坚固,就看各自的手段了。
爬虫在很多场景下的确是有必要的,但现在爬虫技术的使用已经处于失控状态。据说目前网络流量中有60%以上都是由爬虫提供的,这就未免有些过分了。而且有些爬虫即使获取不到任何数据,也会孜孜不倦地继续工作,永不停息。这种失控的爬虫只会不停地消耗资源,对相关的双方都没有好处。
先来假设一段场景。一个普通的网络管理员,发觉网站的访问量有不正常的波动,通常第一反应就是检查日志,查看访问的IP。此时如果发现某一个或几个IP在很短的时间内发出了大量的请求,比如每秒10次,那么这个IP就有爬虫的嫌疑,正常用户是不可能有这种操作速度的,就算是以最快的速度点击刷新按钮也不可能每秒10次。
1、反爬虫在行动
对付这种IP,最简单的方法是一禁了之。实际上不管是Apache还是Nginx都可以对同一IP的访问频率和并发数做出限制,修改Apache或者Nginx的配置文件就可以解决。但在Apache或Nginx中设置禁止访问的IP后,需要重启服务才能生效。所以还需要考虑采用更方便的方法。正常来说,空间主机都有主机管理面板,找到IP限制,将疑似爬虫的IP填进去就可以了,如图1所示。

图1 限制IP
也可以用网站安全狗之类的软件设置黑名单。限制访问IP的方法很多,任意选一种都能达到目的。
这样一禁了之当然简单,但是有时候会误伤正常用户。同一IP大量发送请求,只是有爬虫嫌疑,但并不一定就是爬虫。一个人当然不能每秒10次的发送请求,但10个人呢?要知道目前主流使用的是IPv4协议,IP数量严重不足,很多局域网都是使用NAT共用一个公网IP的,一个大的局域网每秒发送10个请求也不奇怪。反爬虫的目的是过滤爬虫,而不是宁可封锁一千也不放过一个,所以还需要其他的方法来分辨爬虫。
先写一个简单的Python程序来连接网站,再跟浏览器连接网站比较一下。在Burp Suite中可以非常清楚地看到它们的区别。连接程序connWebWithProxy.py的代码如下:
1 #!/usr/bin/env python3
2 #-*- coding:utf-8 -*-
3 import urllib.request
4 import sys
5 proxyDic={'http':'http://127.0.0.1:8080'}
6 def connWeb(url):
7 proxyHandler=urllib.request.ProxyHandler(proxyDic)
8 opener=urllib.request.build_opener(proxyHandler)
9 urllib.request.install_opener(opener)
10 try:
11 response=urllib.request.urlopen(url)
12 htmlCode=response.read().decode('utf-8')
13 except Exception as e:
14 print("connect web faild…")
15 print(e)
16 else:
17 print(htmlCode)
18 if __name__ =='__main__':
19 url=sys.argv[1]
20 connWeb(url)
注意:http://127.0.0.1:8080是Burp Suite的监听端口。
执行命令:
python connWebWithProxy.py study.163.com
执行结果如图2所示。
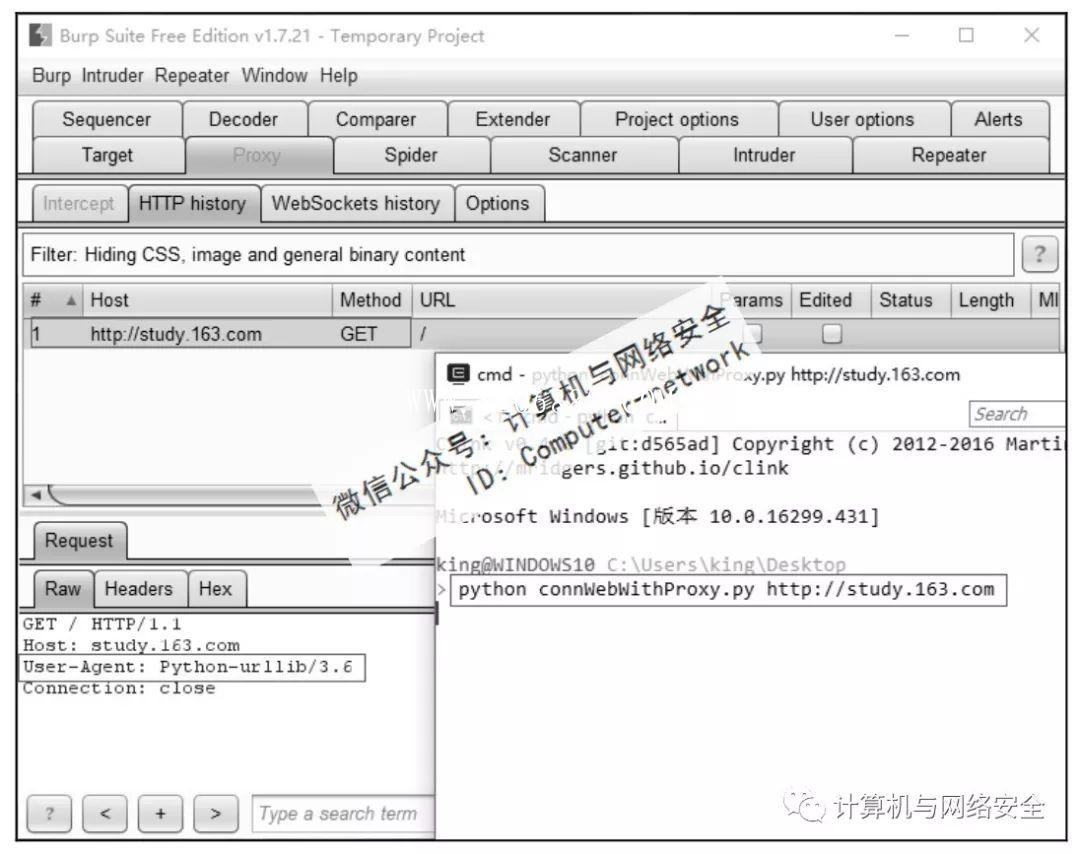
图2 Python程序连接网站
可以看到使用Python程序连接网站时,User-Agent的值是Python-urlib/3.6。在浏览器中,使用Burp Suite的监听端口为代理,连接网站得到的结果如图3所示。
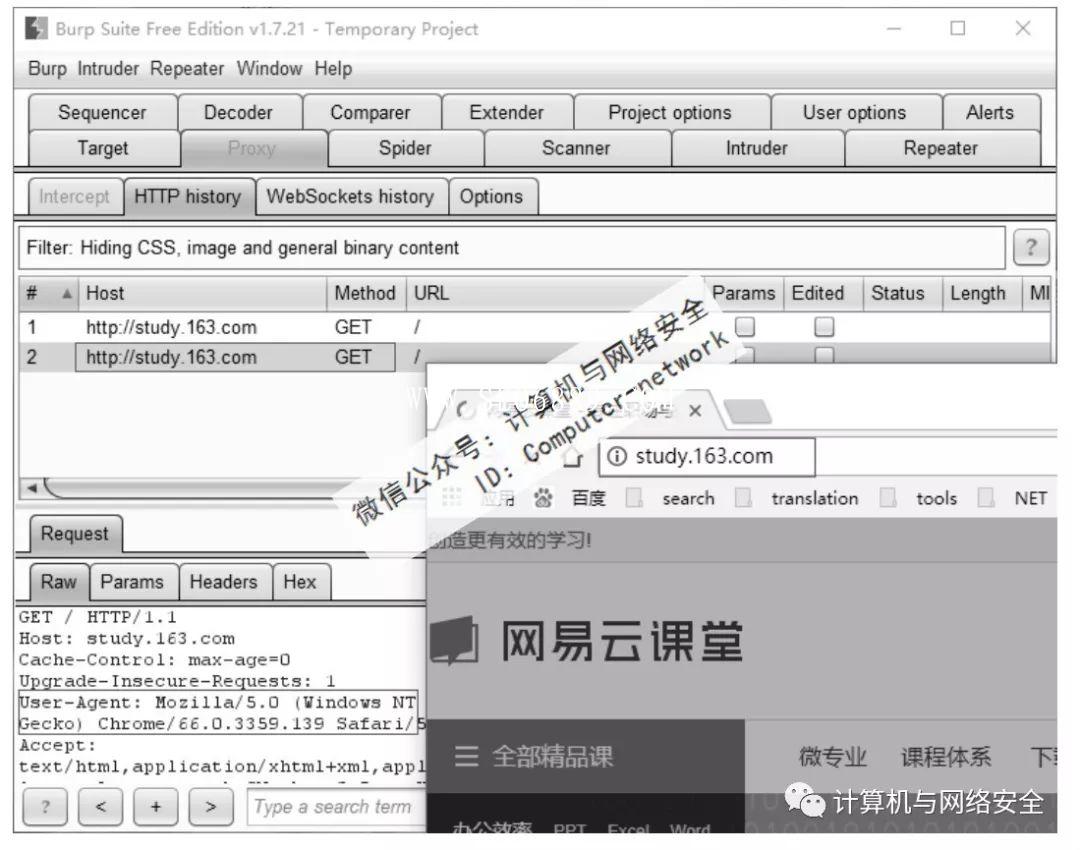
图3 浏览器连接网站
浏览器连接网站时,User-Agent显示的是浏览器的信息。通过对比可以得知,服务器端如果发现请求的User-Agent中含有Python等字符串的,那必定是机器人(Python爬虫)发送的请求。
因此,网管就可以得出结论:凡是在某个时间段频繁连接服务器,并且发送请求的User-Agent中含有Python等字符串的就是爬虫。对这类IP一封了之,必定没错。
2、爬虫的应对
爬虫IP被封锁了,写爬虫的程序员反思了一下,到底是哪个方面露出了马脚。首先该考虑的就是User-Agent和爬虫的时间间隔,这是最容易出漏洞的地方。毕竟User-Agent是如此的明显,而且不停地发送请求,只要网络管理员愿意花点功夫,就一定可以鉴别出爬虫。
已知破绽,那就需要有针对性地修改爬虫程序。
首先,在每次请求时添加一个delay间隔时间。这个时间既要兼顾效率,不宜设置得太长,也不能设置得太短,避免被服务端发觉。一般来说5~10秒都是没问题的。不要使用一个固定值,使用random随机选择delay的值最佳。
其次,收集User-Agent,组成一个User-Agent池。每次发送请求时,从User-Agent池中随机获取一个User-Agent,让服务器认为发送请求的不是网络爬虫,而是一个大型的局域网。这里举一个简单的例子,把connWebWithProxy.py稍微修改一下,最终得到的connWebWithUserAgent.py程序代码如下:
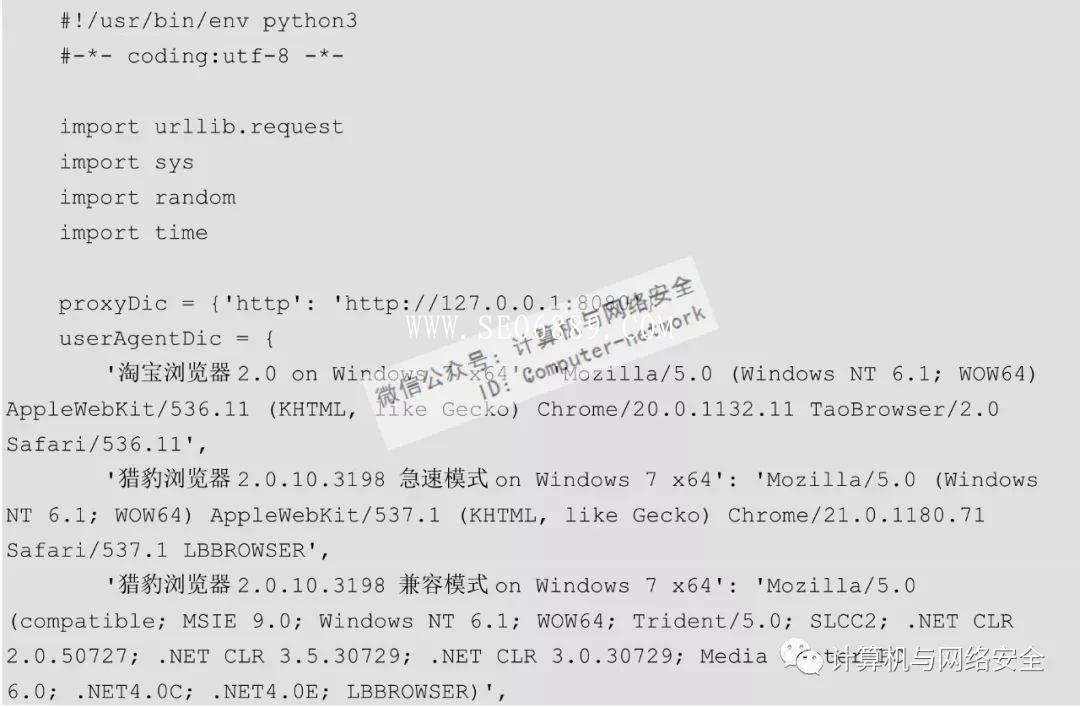


在终端下执行命令:
python connWebWithUserAgent.py http://study.163.com
执行结果如图4所示。
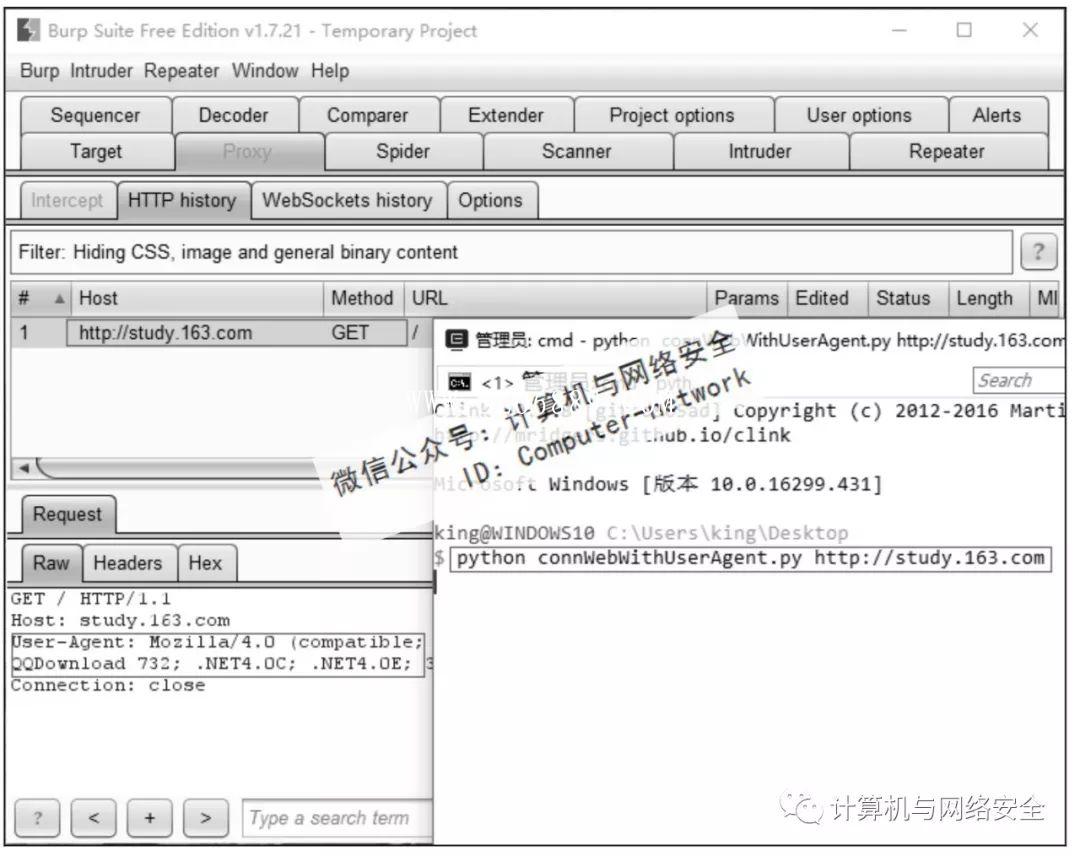
图4 Python隐藏特征连接网站
可以看到,这次连接随机选择了QQ浏览器的User-Agent,让服务端认为本次连接是由QQ浏览器发出的。如果觉得还不够隐蔽,还可以在headers中加上Accept、Host……让爬虫发出的请求更像浏览器。另外,在程序中还随机地暂停了5~10秒,让程序看起来更像是人在操作,尽量避免被服务端的管理员发觉。
本文链接:https://zzc.vikiseo.com/s/2180.html
转载声明:本站发布文章及版权归原作者所有,转载本站文章请注明文章来源!
请发表您的评论